Функционал инструмента позволяет провести расчет необходимых показателей для:
- формирования основного и дополнительных заголовков (Title, Н1, Н2, Н3 etc);
- объема текста, плотности ключевых слов и биграмм в различных зонах документа;
- поиска и количества LSI-терминов, синонимов;
- текстового оформления иллюстраций.
Текстовые зоны документа
Для корректной проработки документа выделены различные текстовые зоны:
- Заголовок документа;
- Заголовок текста (H1);
- Подзаголовки;
- Анкоры - текст ссылок;
- Фрагменты текста;
- Основной текст;
- Вспомогательный текст.
Данные текстовые зоны выделены из-за большего или меньшего влияния на текстовое ранжирование документа, чтобы получить высокую точность анализа.
Запуск инструмента текстового анализа
Чтобы запустить работу инструмента необходимо указать запрос или список запросов и выбрать какие поисковые системы анализировать (в какие ПС собирать “топовые” документы).
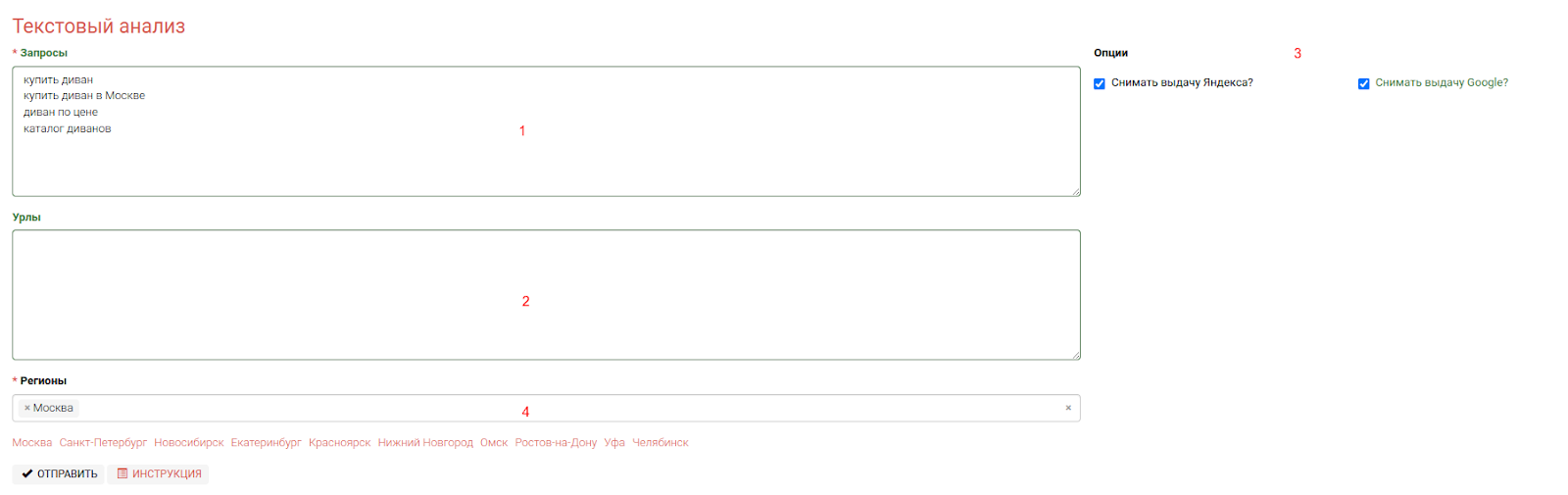
- Список запросов - от качества подбора запросов, зависит и качество отбора конкурентных документов;
- Дополнительные урлы для анализа
- Выбор ПС для анализа (либо сразу в обеих системах)
- Указание региона
Итогом первого запуска данного инструмента будет являтся список собранных конкурентов и их позиции по заданным запросам. Для дальнейшей работы инструмента необходимо выбрать список документов для проведения текстового анализа. Для этого есть два режима текстового анализа:
- По всем документам, которые были собраны
- По “топовым” документам (если хотя бы один запрос находится в пределах Топ-10)
Если список конкурентов не собран, то стоит смягчить параметры для отбора. Например оставить только одну ПС для анализа или уменьшить количество регионов, возможно собранные запросы стоит разделить на разные страницы и убрать неподходящие из анализа.
После изменения параметров перезапустить задачу с новыми данными

Результирующая таблица
Основной результат работы инструмента это таблица “Рекомендуемое ТЗ для копирайтера”. Столбцы таблицы соответствуют текстовым зонам документа указанным в пункте “текстовые зоны документа”. Строки - расчетное количество необходимых вхождений.
Отсутствие какого-либо вхождения в этой таблице означает что оба значения для него (расчетное и актуальное) равны нулю.
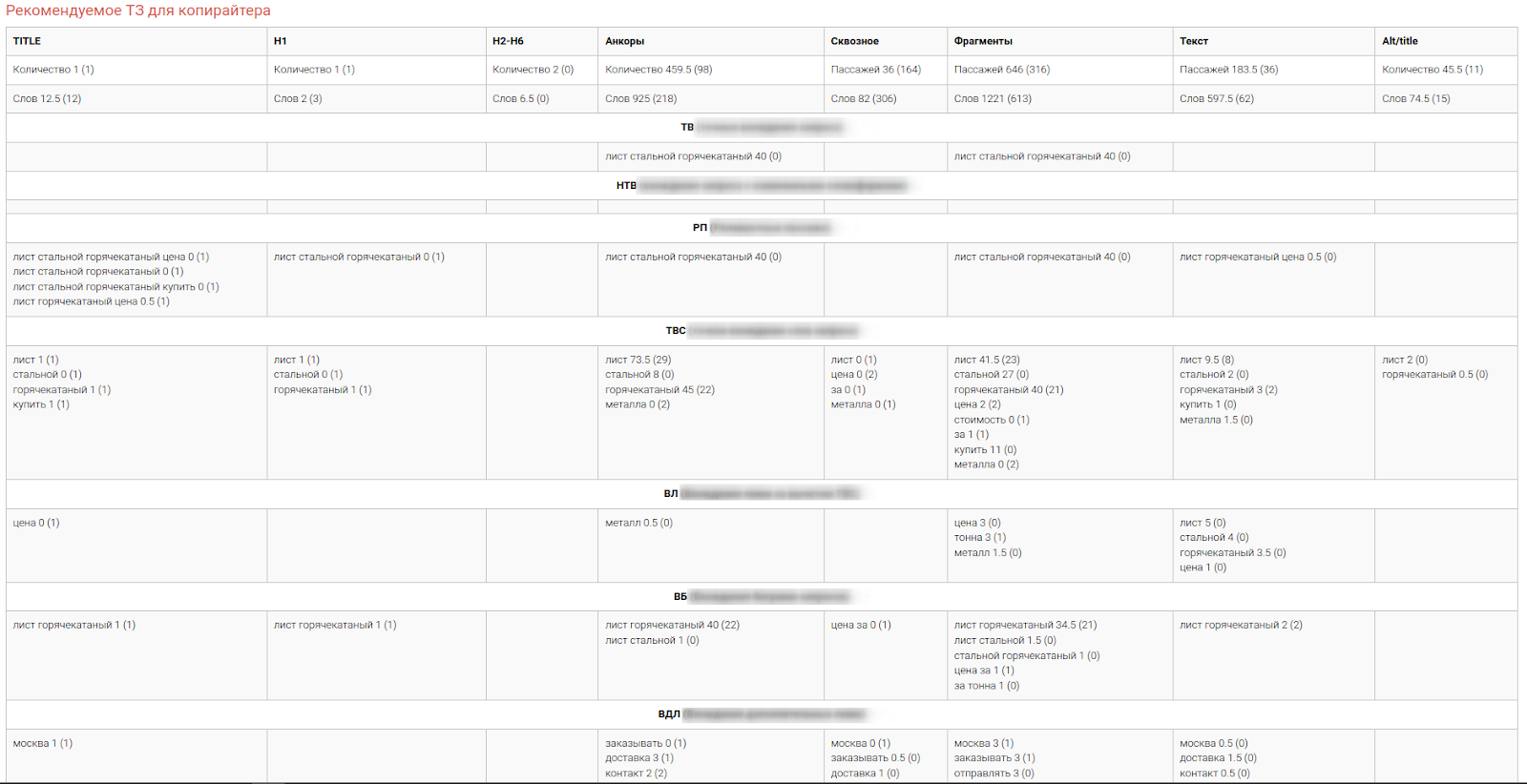
Типы анализируемых вхождений:
Основные:
- Точное вхождение запроса;
- Запрос с измененными словоформами;
- Релевантные пассажи;
- Точное вхождение отдельных слов запроса;
- Вхождение отдельных лемм запроса;
- Вхождение биграмм запроса.
Дополнительные:
- Внезапросные леммы;
- Внезапросные биграммы.
Если есть необходимость посмотреть подробный анализ инструмента, можно нажать на кнопку “детальный анализ документа”, где будут показаны расчетные данные для каждого документа по всем типам анализируемых вхождений для каждой текстовой зоны.